
Why Stateful Applications Need a Cloud-Native Storage Stack

Enterprises are increasingly moving their applications to containerized architectures (typically using Kubernetes, the most popular container orchestration platform in use today). They’re doing this to take advantage of the significant benefits containers provide—namely portability, flexibility, speed of deployment, DevOps agility and resource efficiency.
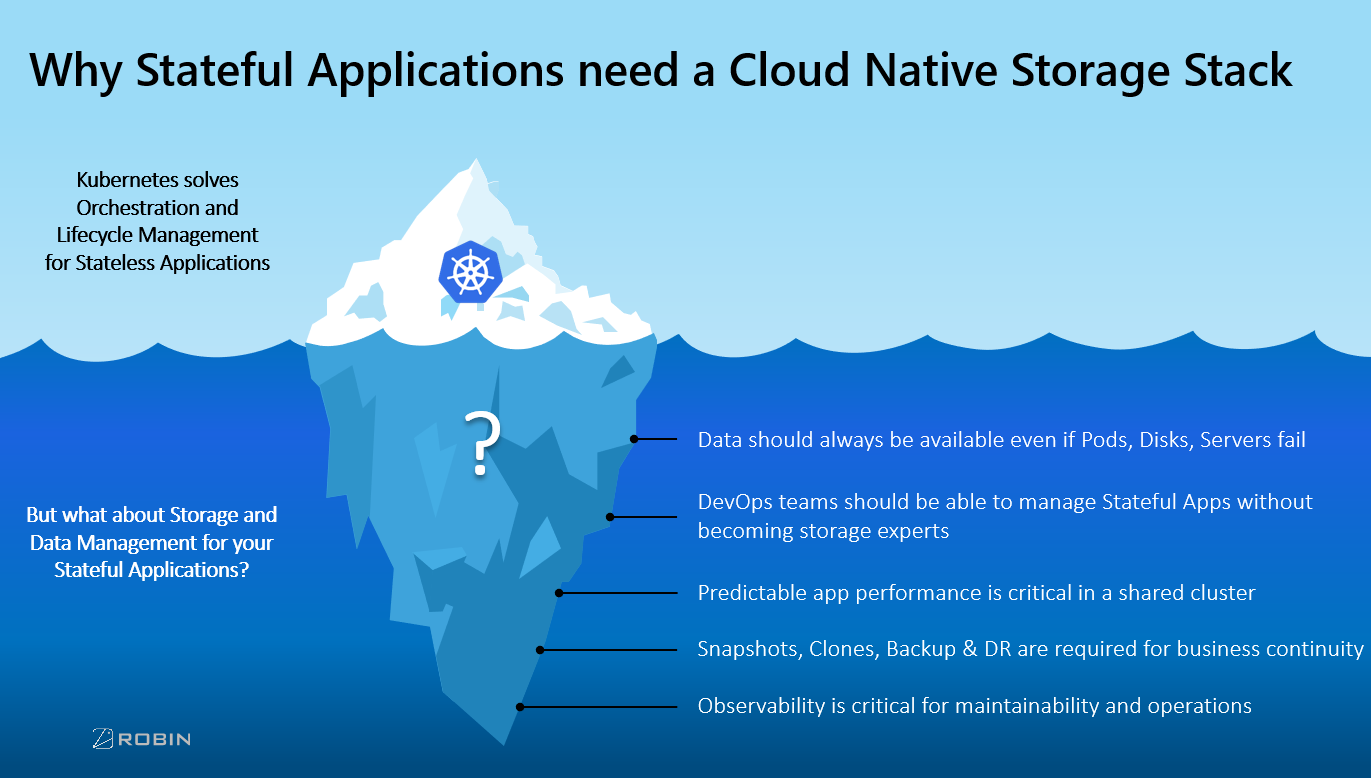
Containers were originally built to be stateless—spun up and down when needed, and therefore “ephemeral.” For this reason, containers are ideal for stateless applications, where applications don’t need to store data and keep a record of previous interactions. Kubernetes does a great job of orchestrating and managing the lifecycle of stateless applications.
Now, however, organizations want to take advantage of the speed, flexibility and efficiency of their Kubernetes platforms for their stateful applications too. Stateful applications—including powerful database and Big Data analytics applications such as Cassandra, MongoDB and MySQL—need persistent data storage so that data and records of interactions survive as the containers they are packaged in “come and go.” Unfortunately, the basic constructs provided by Kubernetes out of the box simply can’t handle these complex storage needs. The storage needs of stateful applications go much deeper.
- Data should always be available, even if pods, disks or servers fail.
- DevOps and DataOps teams should be able to manage stateful applications without becoming storage experts.
- Predictable application performance is critical in a shared cluster.
- Applications should be portable across Kubernetes clusters and environments.
- Observability is critical for maintainability and operations.
Problem is, Kubernetes by itself can’t take care of these complexities. That’s why stateful applications need a cloud-native storage stack. Collectively, these requirements call for a unique solution on top of Kubernetes versus trying to force-fit existing solutions.
This is where Robin Cloud Native Storage (CNS) comes in. Robin.io Cloud Native Storage is a storage and data management solution that makes it easy to deploy and manage complex stateful applications on any flavor of Kubernetes and on any cloud. This includes:
- Capturing the entire state of the application. This includes not just the data (persistentVolumeClaims), but also the metadata (pods, statefulsets, etc.), and configuration (configmaps, secrets, etc.).
- High performance at scale: 2-3x faster than closest competitor, delivering high performance at scale. Only solution to support multi-service affinity, anti-affinity and data locality policies to deliver predictable performance in a shared cluster.
- Best-in-class data resiliency: Most advanced data reliability with strict durability guarantees expected by data-rich applications. Rapid failover even in the event of disk, server, rack and datacenter faults.
Protection against data loss from user errors: User accidently deleted data? Or just want to see what your data looked at a prior date? Checkpoint your entire app before upgrades? CNS provides application-aware snapshots for this. - Disaster Recovery and Business Continuity: Protect against hardware and infrastructure failures by always-incremental backup and restore of entire applications, not just storage.
- Multi-cloud portability: Easily move stateful applications across on-prem and public clouds.
In short, we’re making it super easy for developers and DevOps engineers who use Kubernetes to get the storage and data management capabilities they need using the existing deployment mechanisms they already use for their databases.
To learn more, watch the on-demand webinar, or if you are ready to get started, download CNS for free here.